# 数据类型、函数、基本方法
python是解释型语言
# 变量定义的规则:
- 变量名只能是字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名 【‘and’,‘as’,‘assert’,‘break’,‘class’,‘continue’,‘def’,‘elif’,‘else’,‘except’,‘exec’,‘finally’,‘for’,‘from’,‘global’,‘if’,‘import’,‘in’,‘is’,‘lambda’,‘not’,‘or’,‘pass’,‘print’,‘raise’,‘return’,‘try’,‘while’,‘with’,‘yield’】
# 字符编码
python解释器加载.py文件中的代码时,会对内容进行编码(默认ASCII),ASCII码最多只能表示255个符号,一个字符占一个字节,8位bits
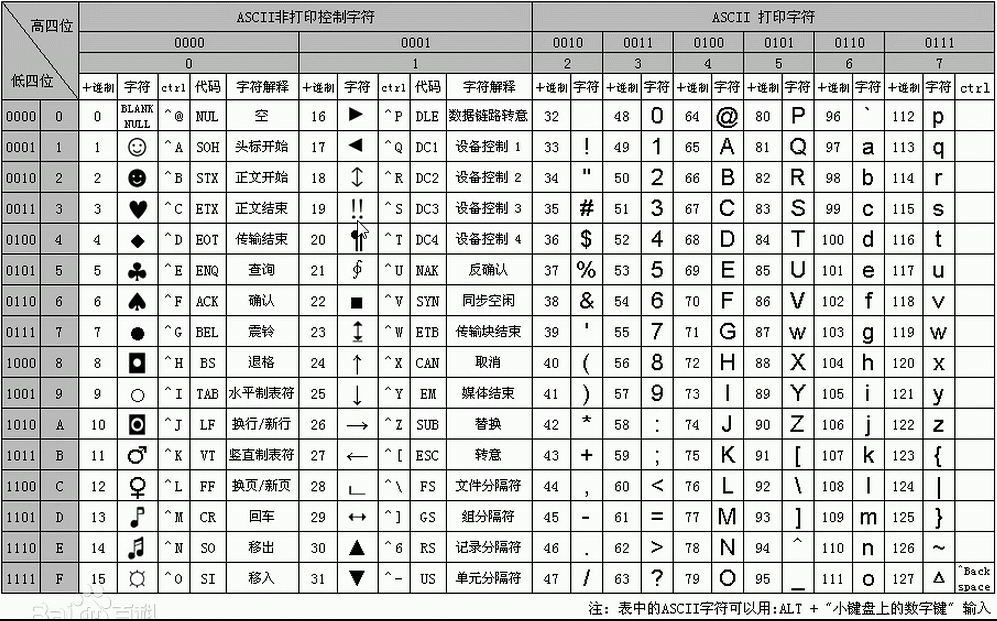
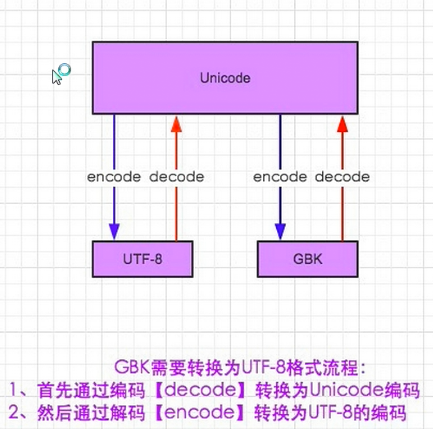
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode,一个字符占两个字节,16位bits UTF-8,,又进步为可变存储字节数,en:1bytes,zh:3bytes
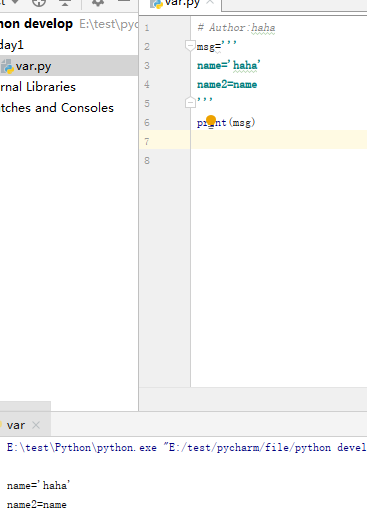
# 注释
当行注释:#被注释内容 多行注释:'''被注释内容''' 注:多行注释也可以多行输出
# 用户交互程序
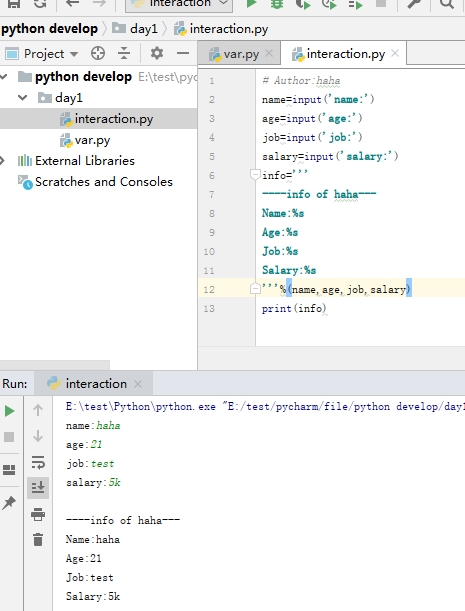
字符串的格式转换:
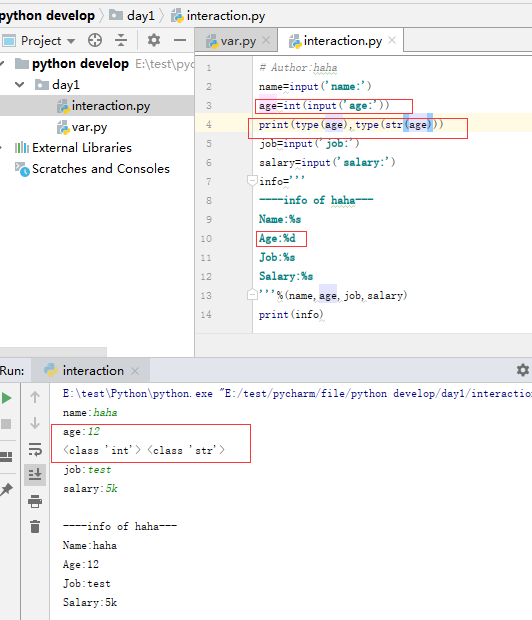
format方式: 1、
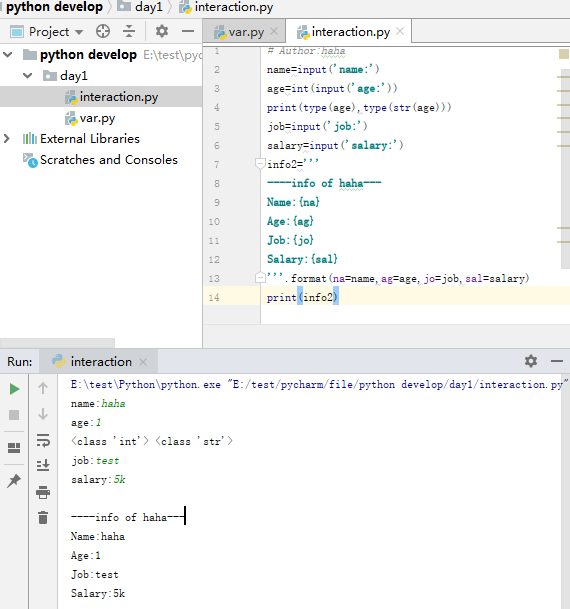
2、
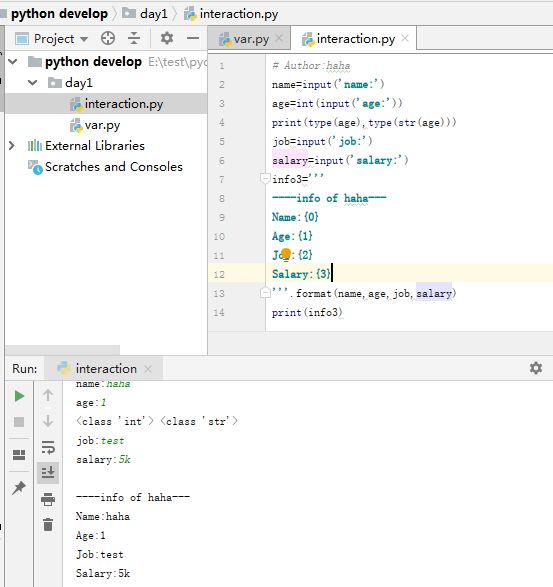
# 密码密文显示
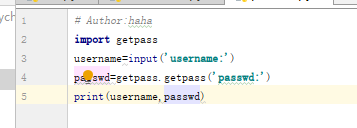
注:不在pycharm中运行,在cmd命令中可以运行
# 循环
# while循环
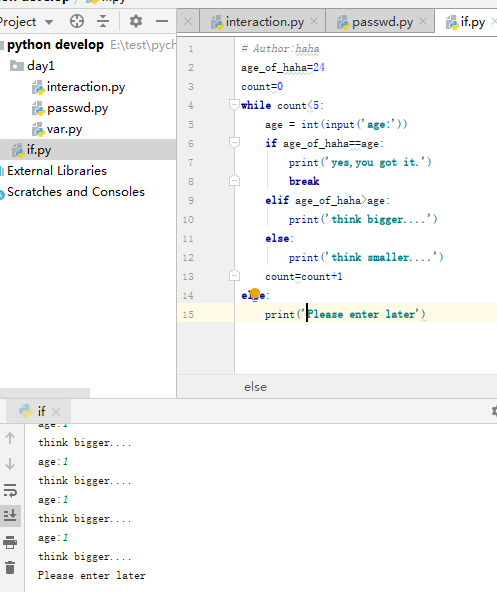
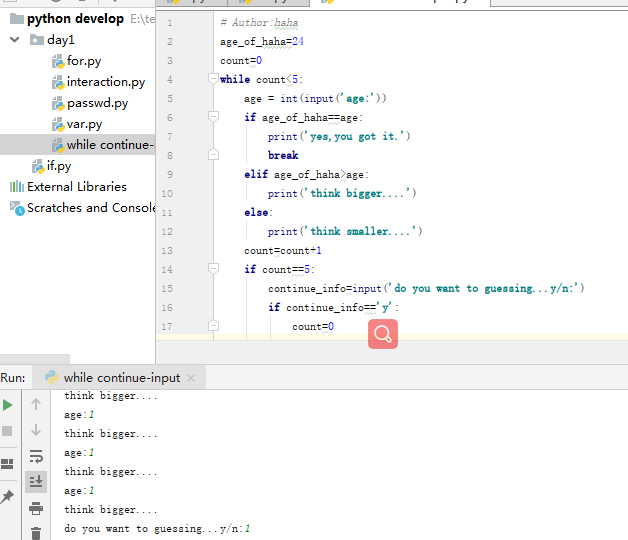
次数达到限制,询问是否继续:
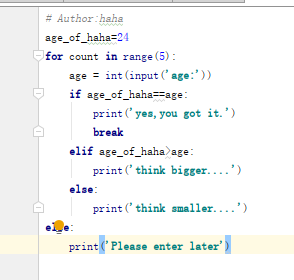
# for循环
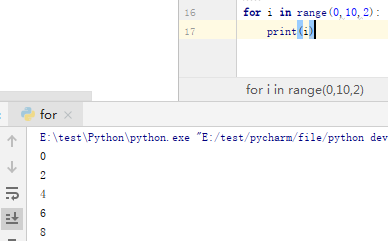
range 打印偶数:
continue
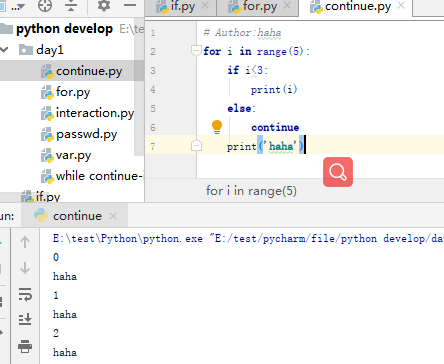
注:continue是跳出本次循环,进入下一次循环;break是结束循环
# 库
python的强大之处在于有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的python库支持
# sys库
打印环境变量
print(sys.path)
打印文件路径
print(sys.argv)
第三方库的安装位置

标准库的安装位置

# OS库
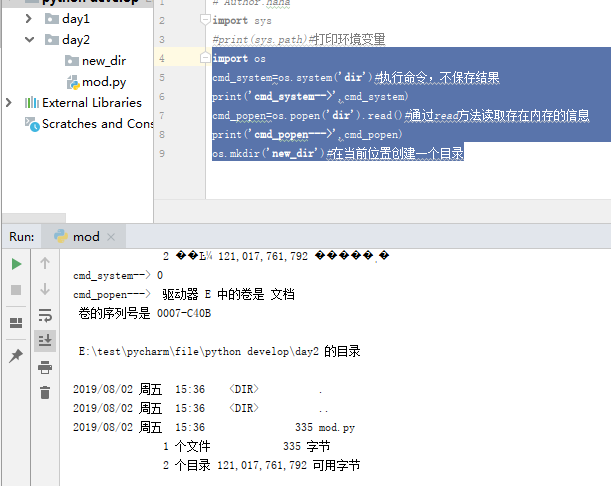
import os
cmd_system=os.system('dir')#执行命令,不保存结果
print('cmd_system--',cmd_system)
cmd_popen=os.popen('dir').read()#通过read方法读取存在内存的信息
print('cmd_popen---',cmd_popen)
os.mkdir('new_dir')#在当前位置创建一个目录
2
3
4
5
6
# 数据类型
###数字 int(整型) 在32位机器上,整数的位数为32位,取值范围为-2^31~ 2^31-1 在64位机器上,整数的位数为32位,取值范围为-2^63~ 2^63-1
long(长整型) python的长整数没有指定位宽
float(浮点型) 浮点数用来处理实数,即带有小数的数字,类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号
修改浮点数的精度:
a=1.3455465457647
a=float('%0.2f'%a)#a=1.35
2
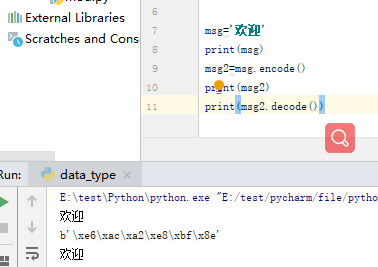
# bytes类型
bytes-》string:decode string-》bytes:encode
# 布尔值
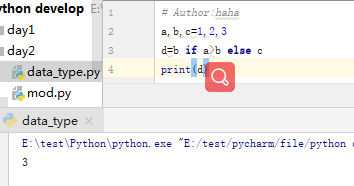
对象的三个特征:id(is)、value(==)、type(isinstance) 真或假(1或0) 三元运算
result=值1 if 条件 else 值2
# 字符串
name='ha\tha'
print('name:',name)
print('len(name):',len(name))
print('name.capitalize():',name.capitalize())#首部大写
print("name.count('h'):",name.count('h'))#指定字母出现的次数
print("name.center(10,'-'):",name.center(10,'-'))#指定字符串的长度,将原本的字符串数据放在中间,不够的数据用‘-’补全
print("name.ljust(10,'-'):",name.ljust(10,'-'))#指定字符串的长度,将原本的字符串数据放在左边,不够的数据用‘-’补全
print("name.rjust(10,'-'):",name.rjust(10,'-'))#指定字符串的长度,将原本的字符串数据放在右边,不够的数据用‘-’补全
print("name.endswith('a'):",name.endswith('a'))#判断字符串是否是指定字母结尾
print('name.expandtabs(tabsize=6):',name.expandtabs(tabsize=6))#将tab键转换为指定个数的空格
print("name.find('a'):",name.find('a'))#找出指定字母的指针
print("name[name.find('a'):]:",name[name.find('a'):])#切片
name2='hello {haha} world'
print('name2:',name2)
print("name2.format(haha='enen'):",name2.format(haha='enen'))
print("name2.format_map({'haha':'enen'}):",name2.format_map({'haha':'enen'}))#通过字典传参
print("'---'.join(['1','2','3']):",'---'.join(['1','2','3']))#将列表转换为字符串并用制动数据隔开
print("'HINIjijhijHI'.lower():",'HINIjijhijHI'.lower())#将大写变小写
print("'HINIjijhijHI'.lower():",'HINIjijhijHI'.lower())
print(r'\nHINIjijhijHI','\nHINIjijhijHI')
print(r"' \nHINIjijhijHI '.lstrip():",' \nHINIjijhijHI '.lstrip())#去掉最左边的回车键
print(r"' HINIjijhijHI\n '.rstrip():",' HINIjijhijHI\n '.rstrip())#去掉最右边的回车键
print(r"' \nHINIjijhijHI \n'.strip():",' \nHINIjijhijHI \n'.strip())#去掉左右的的回车键和空格键
p=str.maketrans('nbyaneuf','09754216')#通过对应数据对字符串进行替换
print('yuan'.translate(p))
print("'HINIjijhijHI'.replace('H','8',1):",'HINIjijhijHI'.replace('H','8',1))#替换指定个数的字符串内数据
print("'1+2+3+4'.split('+'):",'1+2+3+4'.split('+'))#通过字符串内指定数据对字符串进行分割,分割成列表
print("'Haha'.swapcase():",'Haha'.swapcase())#交换字符串大小写
print("'aha yoy'.title():",'aha yoy'.title())#将字符串换成标题格式,每个单词首字母大写
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
输出内容:
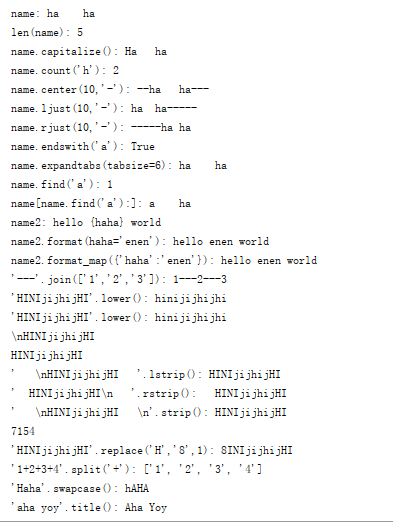
# 列表
name=['haha','enen','lala','yoyo','hengheng','lala']
print(name[0])
print(name[2:4])#切片:顾头不顾尾,包含开头,不包含结束位置
print(name[-1])#取最后一个
print(name[-3:-1])
print(name[-2:])#取最后两个
print(name[:2])#取前面两个
name.append('qq')#插入数据到最后面
print(name)
name.insert(1,'pp')#插入数据到指定位置
print(name)
name[1]='KK'#修改指定位置的数据
print(name)
name.remove('KK')#删除指定数据
print(name)
del name[-1]#删除指定位置数据
print(name)
name.pop(1)#删除指定位置的数据,没有输入下标,默认删除最后一个数据
print(name.index('yoyo'))#查找指定数据的坐标
print(name.count('hengheng'))#查看指定数据的个数
name.reverse()#翻转列表
print(name)
name.sort()#排序(特殊符号,数字,大写字母,小写字母)
print(name)
name_num=[1,2,3,4]
name.extend(name_num)#合并2个列表
print(name,name_num)
name.clear()#清空列表
print(name)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
输出内容:

import copy
name=['haha','enen','lala','yoyo',['yuan','jojo'],'hengheng','lala']
print(name[0:-1:2])#切片隔一个打印一个
#print(name[::2])#同上
name2=name.copy()#浅copy,复制第一层,其他的多层数据都是copy的内存地址
name3=copy.deepcopy(name)#深copy,全部复制,复制的就是数据
print(name3)
print(name2)
name[2]='啦啦'
print(name)
print(name2)
print(name3)
name[4][0]='YUAN'
print(name)
print(name2)
print(name3)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
输出内容:

# 元组
元组和列表差不多,也是存一组数,不过它一旦创建,便不能修改,所以又叫只读列表 它只有2个方法,一个是count,一个是index;
name=('haha','enen','lala')
# 集合
集合是一个无序的,不重复的数据组合,他的主要作用如下:
- 去重,把一个列表变成集合,就自动去去重了
- 关系测试,测试两组数据之间的交集、差集、并集等关系
# Author:haha
list_1=[1,4,2,6,7,9,0,7,4,3,0]
list_1=set(list_1)
print('list1',list_1)
list_2=set([2,3,4,55,7,332])
print('list2',list_2)
list_3=set([0,1])
print('list_3',list_3)
#关系测试
print(list_1.intersection(list_2))#取交集
print('&交集',list_1&list_2)
print(list_1.union(list_2))#并集
print('|并集',list_1|list_2)
print(list_1.difference(list_2))#差集,list_1有,list_2没有的数据
print('1-2:-差集',list_1-list_2)
print(list_2.difference(list_1))#差集,list_2有,list_1没有的数据
print('2-1:-差集',list_2-list_1)
print(list_3.issubset(list_1))#判断list_3是否是list_1的子集
print(list_1.issuperset(list_3))#判断list_1是否是list_3的父集
print(list_1.symmetric_difference(list_2))#对称差集,将list_1、list_2中都互相没有的取都出来
print('^对称差集',list_1^list_2)
#其他遗漏关系
print('----------')
list_4=set([0,3])
print(list_3.isdisjoint(list_4))#判断list3是否和list4有交集,如果有,返回FALSE
list_3.add(999)
print('add 1项',list_3)
list_3.update([5,6,7])
print('update 多项',list_3)
#如果该元素不存在于集合中,则会抛出KeyError;如果存在集合中,则会移除该元素并返回None。
print('remove指定删除元素',list_3.remove(7))
#如果该元素不存在于集合中,则不会抛出KeyError;如果存在集合中,则会移除该元素并返回None。
print('discard指定删除元素',list_3.discard(5))
print('pop随机删除元素,并返回被删除的元素',list_3.pop())
print('len',len(list_3))
print(list_3)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
输出结果:

# 字典
字典的特性: ·dict是无序的 ·key必须是唯一的,所以天生去重
info={
'name':'haha',
'age':12,
'sex':'female'
}
info['name']='enen'#修改现有数据
print(info)
info['ID']='1'#添加数据
print(info)
print(info.keys())#打印所有的key
print(info.values())#打印所有的values
info.setdefault('pp','yoyo')#字典中取key值,能取到就返回value值,没取到,就创建key值,及新value值
print(info)
print('name' in info)#判断指定key是否在字典中
print(info.get('name'))#查找指定key值value,存在打印,不存在,打印none
print(info.get('oo'))
del info['ID']#删除指定key数据
print(info)
info.pop('name')#删除指定key数据
print(info)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
输出内容:

a={'a':'aa','b':'bb','c':'cc'}
b={'a':'haha',1:11,2:22}
a.update(b)#将b合并大a中,如果有相同key值,b的value替换a中value值
print(a)
print(a.items())
c=dict.fromkeys([6,7,8],'test')#初始化字典
print(c)
#字典的循环
for i in a:#效率更高
print(i,a[i])
for i,j in a.items():
print(i,j)
2
3
4
5
6
7
8
9
10
11
12
13
输出内容:

# 进制转换
二进制数与十六进制数之间如何互相转换 16位表示方法:
| 十进制数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 十六进制数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| 二进制数 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
二进制转换成十六进制方法:取四合一,如
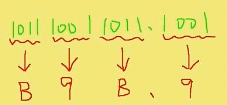
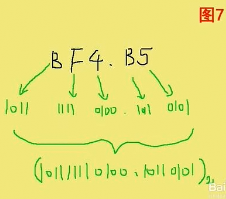
16进制的表示法:比BH表示16进制数11;0x53表示16进制53

在向左(或向右)取四位时,取到最高位(最低位)如果无法凑足四位,就可以在小数点的最左边(或最右边)补0
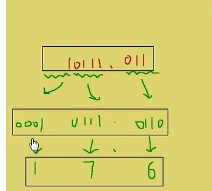
十六进制转二进制:一分四
# 进制表示
二进制:0b(二进制数) 如:0b10=2(十进制数)
八进制:0o(八进制数) 如:0o10=8(十进制数)
十六进制:0x(十六进制数) 如:0x10=16(十进制数)
十进制:(十进制数) 如:10=10(十进制数)
2
3
4
# 转换
bin(除二进制数)->二进制
int(除十进制数)->十进制
hex(除十六进制数)->十六进制
oct(除八进制数)->八进制
ord(除ascll码)->ascll码
2
3
4
5
# 运算符
'hello'+'world'
#helloworld
[1,2,3]*3
#[1, 2, 3, 1, 2, 3, 1, 2, 3]
3-1
#2
3/2
#1.5
3//2(整除)
#1
5%2(求余)
#1
5**2(平法)
#25
5**5(次方)
#3125
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 赋值运算符(先计算再赋值)
=、-=、+=、*=、/=、//=、%=、**=
# 逻辑运算符
优先级: 高:not(反) 中:and(且) 遇假为假 低:or(或) 遇真为真
# 位运算符(把数字当做二进制进行计算)
&(按位与)->10&11->10 见0是0
|(按位或)->10|11->11 见1是1
^(按位异或)
~(按位取反)
<<(左移动)
>>(右移动)
2
3
4
5
6
# 文件操作
对文件操作流程 1、打开文件,得到文件句柄并复制给一个变量 2、通过句柄对文件进行操作 3、关闭文件
#读文件
file=open('buweixia','r',encoding='utf-8')#文件句柄,默认读模式
data=file.read()#执行后文件指针已经知道文件末尾
data2=file.read()#所以data2为空
print(data)
print('---data2---',data2)
file.close()
file6=open('buweixia2','rb')#以二进制模式读取文件
print(file6.readline().strip())
print(file6.readline().strip())
file6.close()
#写文件
file2=open('buweixia2','w',encoding='utf-8')#使用写模式,是创建,如果文件存在,就会覆盖之前内容,如果文件不存在,就会创建文件
file2.write('不谓侠\n')
file2.write('歌词\n')
file2.close()
file7=open('buweixia2','wb')#以二进制模式写文件
file7.write('编曲:潮汐-tide\n')
file7.close()
#可读可写
file5=open('buweixia2','r+',encoding='utf-8')#使用读写模式,是创建,如果文件不存在,就会创建文件
print(file5.readline().strip())
print(file5.readline().strip())
file5.write('不谓侠\n')
file5.write('歌词\n')
file5.close()
#追加文件
file3=open('buweixia2','a',encoding='utf-8')#使用追加模式,是创建,如果文件不存在,就会创建文件
file3.write('词:迟意 ')
file3.write('曲:潮汐-tide\n')
file3.close()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
file4=open('buweixia','r',encoding='utf-8')#文件句柄,默认读模式
#打印前5行内容
print('------打印前5行内容------')
for i in range(5):
print(file4.readline().strip())
#循环文件,大文件的话,占内存
print('--------循环文件,操作第10行---------')
for index,line in enumerate(file4.readlines()):
if index==9:
print('-----分割线-------')
continue
print(line.strip())
#高效循环文件,不占内存
file4=open('buweixia','r',encoding='utf-8')#文件句柄,默认读模式
count=0
for line in file4:
if count==9:
print('-----分割线-------')
count += 1
continue
count+=1
print(line.strip())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
file=open('buweixia','r',encoding='utf-8')#文件句柄,默认读模式
print(file.tell())#打印当前指针的位置
print(file.read(5))#指定读取文件字符个数
print(file.tell())
file.seek(22)#移动指针到文件开头位置
print(file.readline())
print(file.encoding)#打印文件的编码格式
print(file.name)#打印文件名
print(file.flush())#实时更新硬盘数据
#例:
import sys,time
for i in range(10):
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.1)
file.truncate(10)#没有参数,就清空文件;有参数,就从指定指针位置截断文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#修改文件
f1=open('buweixia','r',encoding='utf-8')
f_new=open('buweixia_update','w',encoding='utf-8')
for line in f1:
if '潮汐-tide' in line:
line=line.replace('潮汐-tide','haha')
f_new.write(line)
f1.close()
f_new.close()
2
3
4
5
6
7
8
9
with:为了避免文件打开后忘记关闭,就通过with管理上下文
#可以同时打开多个文件
with open('buweixia','r',encoding='utf-8') as f,\
open('buweixia','r',encoding='utf-8') as f2:
for line in f:
print(line)
print(f2.readline())
2
3
4
5
6
# 函数
编程语言中的函数定义:函数是逻辑结构化和过程化的一种编程方法。
#python中函数定义方法
def test(x):
'The function definitions'
x+=1
return
'''
def:定义函数的关键字
test:函数名
():内可定义形参
'':函数描述(非必要,但是强烈建议为你的函数添加描述信息)
x+=1:泛指代码块或程序处理逻辑
return:定义返回值
'''
2
3
4
5
6
7
8
9
10
11
12
13
使用函数的三大优点: 1、代码重用 2、保持一致 3、可扩展性
函数的返回值:
- 返回值数=0;返回None
- 返回值数=1;返回object
- 返回值数>0;返回tuple
# 传参
#默认参数特点:调用函数的时候,默认参数非必须传递
def test1(x=1):
print('test1',x)
test1()
#输出:1
#接收N个位置参数,转换成元组形式
def test2(*args):
print(args)
print(type(args))
test2(1,2,3,4)
test2(*[1,2,3,4,5])
#输出:(1, 2, 3, 4)
# <class 'tuple'>
# (1, 2, 3, 4, 5)
# <class 'tuple'>
#**kwargs:把N个关键字参数,转换成字典的方式
def test3(name,age=18,**kwargs):
print(name)
print(age)
print(kwargs)
test3('haha',sex= 'm',hobby='testing')
#输出:
# haha
# 18
# {'sex': 'm', 'hobby': 'testing'}
def test4(**kwargs):
print(kwargs)
test4(**{'name':'haha','sex':'m'})
#输出:{'name': 'haha', 'sex': 'm'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 局部变量和全局变量
- 在子程序中定义的变量为局部变量,在程序的一开始定义的变量为全局变量
- 全局变量的作用域是整个程序,局部变量作用域是定义该变量的子程序
- 当全局变量与局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其他地方全局变量起作用
#局部变量,所在函数就是这个变量的作用域
def test1(name):
print('before change %s'%name)
name='HAHA'
print('after change %s'%name)
name='haha'
test1(name)
print(name)
#输出:
# before change haha
# after change HAHA
# haha
2
3
4
5
6
7
8
9
10
11
12
13
#全局变量
def test2():
global name #申明变量的类型
print('before change %s'%name)
name='HAHA'
print('after change %s'%name)
name='haha'#全局变量
test2()
print(name)
#输出:
# before change haha
# after change HAHA
# HAHA
2
3
4
5
6
7
8
9
10
11
12
13
14
# 递归
在函数内部,可以调用其他函数,如果一个函数在内部调用自己本身,这个函数就是递归函数 递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过高会导致栈溢出
def test(n):
print(n)
if int(n/2)>0:
return test(int(n/2))
print("->",n)
test(10)
#输出:
# 10
# 5
# 2
# 1
# -> 1
2
3
4
5
6
7
8
9
10
11
12
# 高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另外一个函数作为参数,这种函数就叫高阶函数
def add(a,b,f):
return f(a)+f(b)
res=add(2,-6,abs)#abs为取绝对值
print(res)
#输出:8
2
3
4
5
6
# 装饰器
定义:本质是函数,装饰其他函数就是为其他函数添加附加功能 原则:
- 不能修改被装饰的函数的源代码
- 不能修改被装饰的函数的调用方式 简单装饰器:
import time
def timer(func):
def wrapper():
print('before time',time.time())
func()
print('after time',time.time())
return wrapper
@timer
def test():
time.sleep(1)
print('haha')
test()
2
3
4
5
6
7
8
9
10
11
12
13
14
复杂装饰器:
username='haha'
passwd='123'
def login(type):
def outwrapper(func):
def wrapper(*args,**kwargs):
if type=='qq':
name=input('your username:')
psd=input('your password:')
if name==username and passwd==psd:
print('welcome...')
return func(*args, **kwargs)
else:print('username or passwd error')
else:
print('还不支持此登录方式!')
return wrapper
return outwrapper
@login(type='qq')
def first_page(name):
print('this is first page ',name)
@login(type='weixin')
def second_page():
print('this is second page ')
first_page('haha')
second_page()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 生成器
- 只有在调用时才会生成相应的数据
- 只记录当前位置
- 只有一个next()方法
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
2
3
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
2
3
4
5
6
7
8
复杂生成器:
def cals(max):
n=0
a=0
b=1
while n<max:
yield b
a,b=b,a+b
n+=1
return 'done'
print(cals(10))
2
3
4
5
6
7
8
9
10
11
输出结果:
<generator object cals at 0x0000000001E1CA20>
捕获错误信息:
def cals(max):
n=0
a=0
b=1
while n<max:
yield b
a,b=b,a+b
n+=1
return 'done'
c=cals(6)
while True:
try:
print(next(c))
except StopIteration as s:
print('StopIteration',s.value)
break
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
输出结果:
1
1
2
3
5
8
StopIteration done
2
3
4
5
6
7
还可通过yield实现在单线程的情况下实现并发运算的效果:
import time
def eat(name):
print('%s,来了,点了包子'%name)
while True:
num=yield
print('%s正在吃了第%s个包子'%(name,num))
def make():
c=eat('A')
c2=eat('B')
c.__next__()
c2.__next__()
print('包子拿来了')
time.sleep(1)
for i in range(8):
time.sleep(1)
print('上了第%s个包子'%i)
c.send(i)
c2.send(i)
make()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
输出结果:
A,来了,点了包子
B,来了,点了包子
包子拿来了
上了第0个包子
A正在吃了第0个包子
B正在吃了第0个包子
上了第1个包子
A正在吃了第1个包子
B正在吃了第1个包子
上了第2个包子
A正在吃了第2个包子
B正在吃了第2个包子
上了第3个包子
A正在吃了第3个包子
B正在吃了第3个包子
上了第4个包子
A正在吃了第4个包子
B正在吃了第4个包子
上了第5个包子
A正在吃了第5个包子
B正在吃了第5个包子
上了第6个包子
A正在吃了第6个包子
B正在吃了第6个包子
上了第7个包子
A正在吃了第7个包子
B正在吃了第7个包子
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 迭代器
- 可以直接作用于for循环的对象统称为可迭代对象:Iterable
- 可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
- 生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
2
3
4
# 内置方法
print('all:',all([2,0,6]))#数据内,有假,就为假
print('any:',any([2,0,6]))#数据内,有真,就为真
print('bin:',bin(8))#将十进制转为二进制
print('hex:',hex(8))#将十进制转成十六进制
print('oct:',oct(8))#将十进制转成八进制
def test():pass
print('callable:',callable(test))#判断数据是否可以调用
print('chr:',chr(77))#输入ASCII码,找出对应字符
print('ord:',ord('m'))#输入字符,找出对用ASCII码
print('dir:',dir([]))#取出数据有哪些方法
print('eval:',eval("{'name':'haha'}"))#将字符串转成表达式
print('pow:',pow(2,8))#取出指定数据的指定次幂
print('round:',round(2.445,2))#保留几位小数
print('frozenset:',frozenset([1,23,4,3,5,7,1]))#冻结集合,使集合不能更改
2
3
4
5
6
7
8
9
10
11
12
13
14
输出结果:
all: False
any: True
bin: 0b1000
hex: 0x8
oct: 0o10
callable: True
chr: M
ord: 109
dir: ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
ecal: {'name': 'haha'}
pow: 256
round: 2.44
frozenset: frozenset({1, 3, 4, 5, 7, 23})
2
3
4
5
6
7
8
9
10
11
12
13
a=bytearray('456778',encoding='utf-8')
print(a)
print(a[0])
a[0]=99
print(a)#修改字符串
#输出:
# bytearray(b'456778')
# 52
# bytearray(b'c56778')
res=filter(lambda n:n>5,range(10))#
for i in res:
print(i)
#输出:
# 6
# 7
# 8
# 9
res2 = map(lambda n: n > 5, range(10))#
for i in res2:
print(i)
#输出:
# False
# False
# False
# False
# False
# False
# True
# True
# True
# True
from functools import reduce
res3=reduce(lambda x,y:x+y,range(100))
print(res3)
#输出:
# 4950
a={3:4,-6:3,2:7}
print(sorted(a.items()))#使字典变为列表按key值排序
print(sorted(a.items(),key=lambda x:x[1]))#使字典变为列表按value值排序
#输出:
# [(-6, 3), (2, 7), (3, 4)]
# # [(-6, 3), (3, 4), (2, 7)]
a=[1,2,3,4,5,6]
b=['a','b','c','d']
for i in zip(a,b):
print(i)
#输出:
# (1, 'a')
# (2, 'b')
# (3, 'c')
# (4, 'd')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 序列化和反序列化(json、pickle)
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
- Json模块提供了四个功能:dumps、dump、loads、load
- pickle模块提供了四个功能:dumps、dump、loads、load
import json
data={'a':1,'b':2}
j_str=json.dumps(data)
print(j_str)
j_json=json.loads(j_str)
print(j_json['a'])
with open('./test.txt','w') as f:
json.dump(data,f)
with open('./test.txt','r') as f1:
data_j=json.load(f1)
print(data_j['b'])
#输出结果:
{"a": 1, "b": 2}
1
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import pickle
data={'a':1,'b':2}
p_str=pickle.dumps(data)
print(p_str)
p_json=pickle.loads(p_str)
print(p_json['a'])
with open('./test.txt','wb') as f:#以二进制形式存入文件
pickle.dump(data,f)
with open('./test.txt','rb') as f1:
data_j=pickle.load(f1)
print(data_j['b'])
#输出结果:
b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02K\x02u.'
1
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
← 计算机网络基础小知识 模块 →